How can we create a light, easy to use system that allows users to get data, fix any mistakes, and use their data as fast as possible, without bogging down their workflow with our need for corrections on our extraction process?
How it went
The process of pulling information from certain closing documents in commercial real estate is complex and often done by hand. These documents are written in human readable, natural language – not always the friendliest for machine learning systems to parse.
Our current process of receiving a document and returning data was a one-way street. There was no way for users to let us know what corrections they made to their information. However, this corrected information would be immensely valuable in helping our machine learning platform grow and learn over time.
The team, including a product manager and another UX researcher besides myself, worked to talk with dozens of people in the industry around how they managed their data extraction and management flows. We wanted to understand what people needed, how they used the data, and what programs they used to do this in.
At the same time – we also needed to understand people’s perspective of machine learning. How ‘exact’ did they expect the results to be from a machine? What aspects of the process helped people trust the results of a machine-based data extraction? What hurt that trust?
Initial findings spoke to complex and contradictory expectations – perfect results were expected, but later research showed that perfectly transcribed results were rarely recognized on their own merit. Merely showing the user the data, even if it was perfect, exactly where they needed it, would not be enough for users to trust the results.
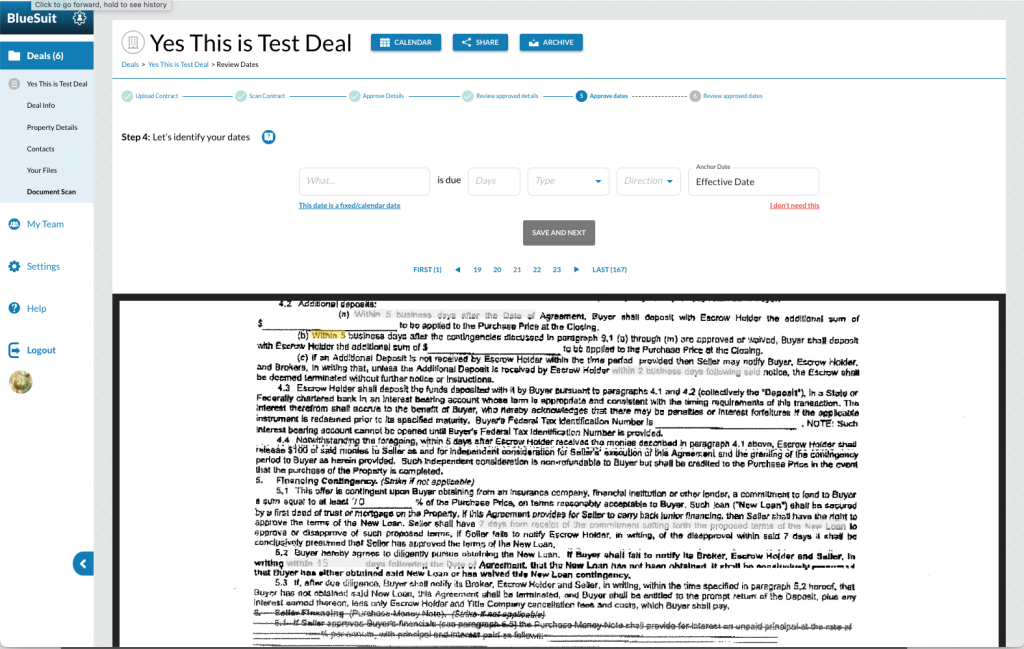
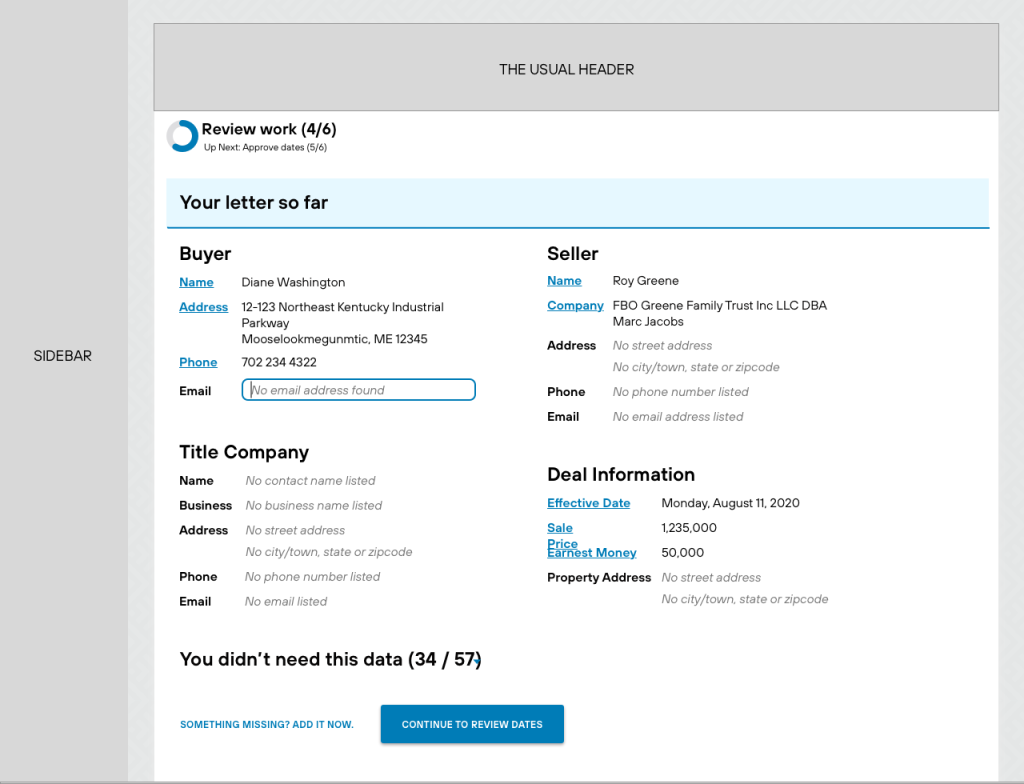
Based on these results, I drafted on building a workflow that would speak to conventions and patterns the users would find familiar – upload the document, and review the data in Excel-like tables. Dates would be presented at the end so the user could review the results of the ML/AI process, and the user would have the final say on the data and dates. Then they would have the ability to send or download a hard copy to parties that prefer letters/hard documents.
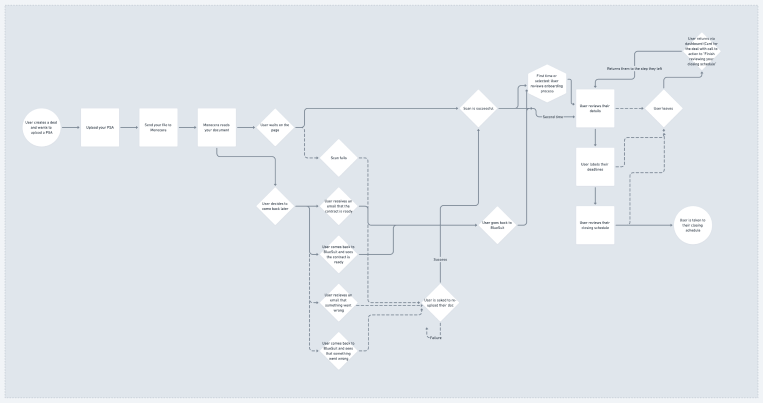
Technical constraints of the model; however, prevented the exact implementation of this workflow. The (newly built) model needed more training before it could accurately pull and contextualize data. We needed to build a process that would both meet the users needs (quickly processing important data), and teach the model at the same time (encouraging people to interact with the ‘labeling’ process, and not skip it).
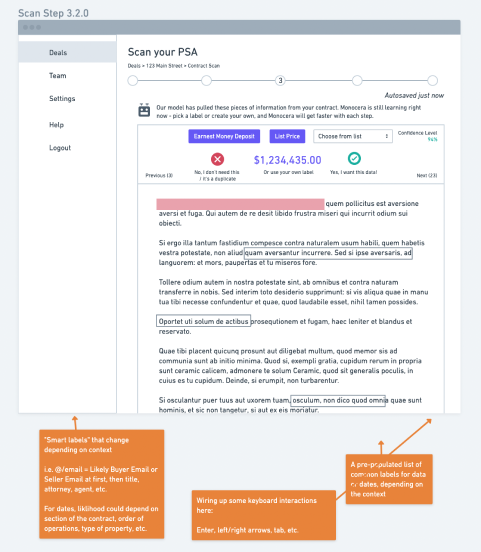
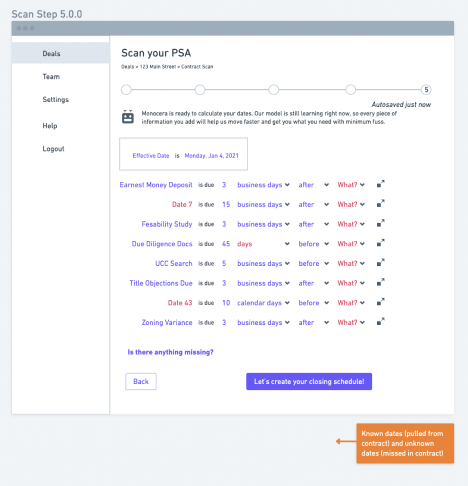
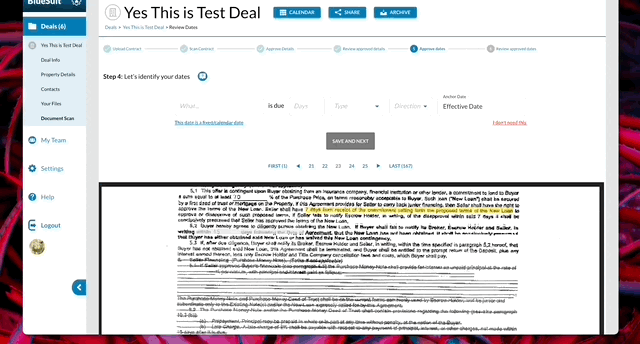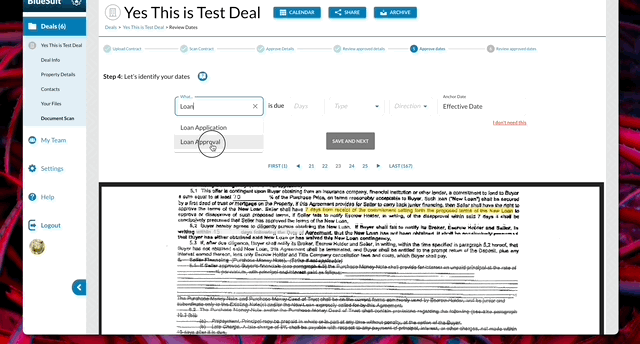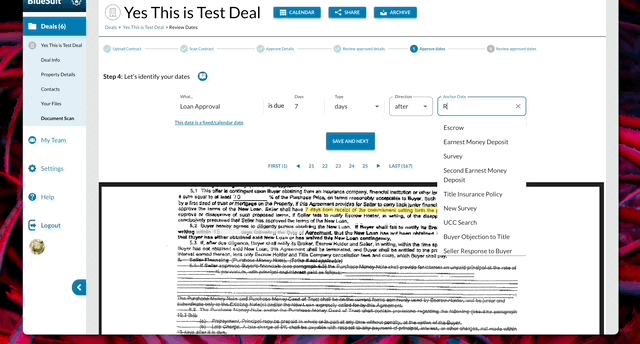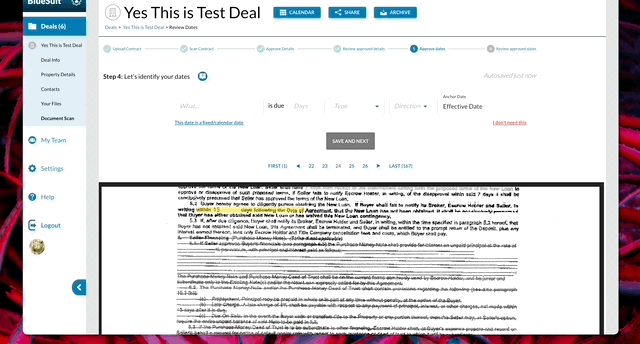
With the team, we built a step-by-step solution that would allow users to review a piece of data, label it, and progress through the results from the model. We focused on requiring the minimal amount of typing, clicking or reading – leveraging several micro patterns from Google Material to ensure the entire process was familiar and easy.
We went through several testing and building iterations before we landed on our final form.
Part of the challenge of testing was that part of the development of this tool took place during the Covid-19 pandemic in an industry that was extremely concerned about the effects the pandemic would have on their jobs and companies. Users were extremely hard to reach, short on time, and worried about other, bigger things.
The UX Researcher and I developed a multi-prong approach to this situation.
We used an AI-based tool to simulate heat maps of where a users’ eye would fall on the page, and rate the complexity.
We conducted usability testing with naive users to ensure that our product made sense. We did continue to conduct interviews and reach out to possible users, while understanding that these are difficult times and we may not be able to rely as much on direct feedback.
Our design team of 2 worked with developers to bring this plan to life. Some of the challenges of implemented included custom components for very specific interactions, and balancing level of effort of development against the need for some fairly complex features.
Currently, the process is built but not live. There are a few different places this feature could land – either as a user facing tool for processing data pulled from agreements, or as an internal tool for labelers to help speed up the machine model’s learning process.